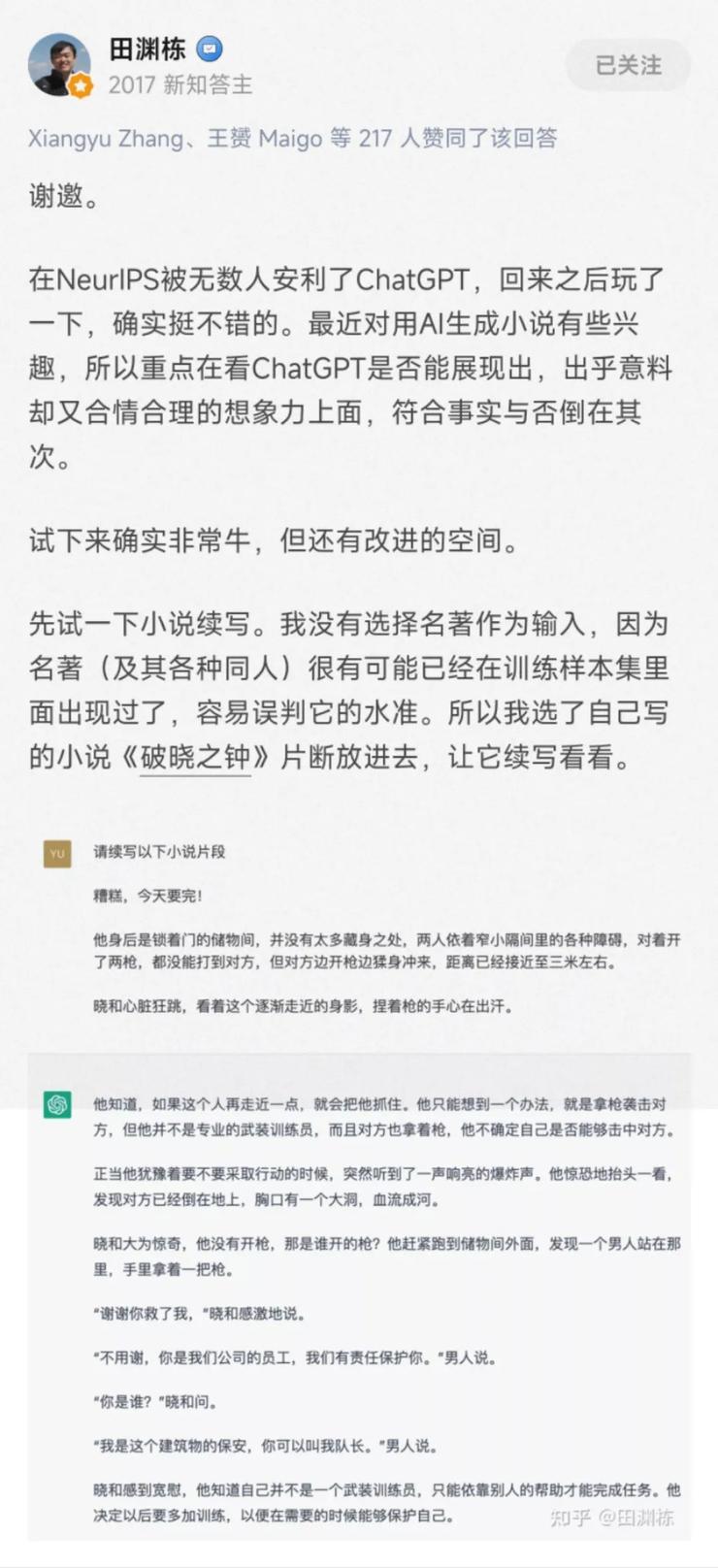
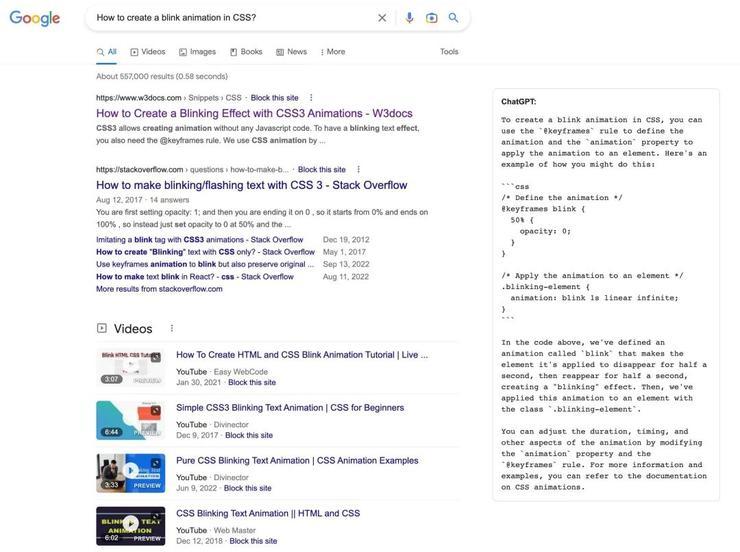
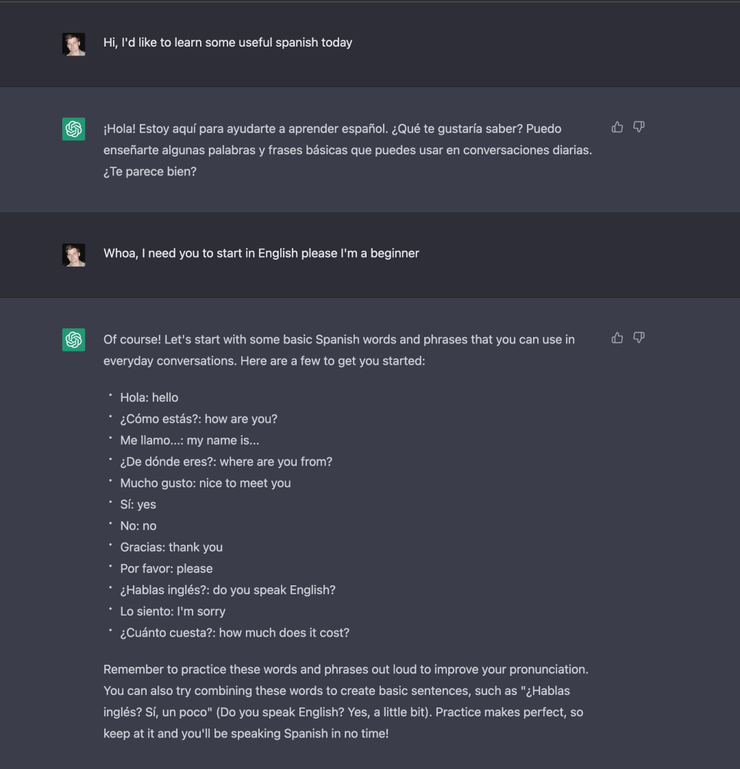
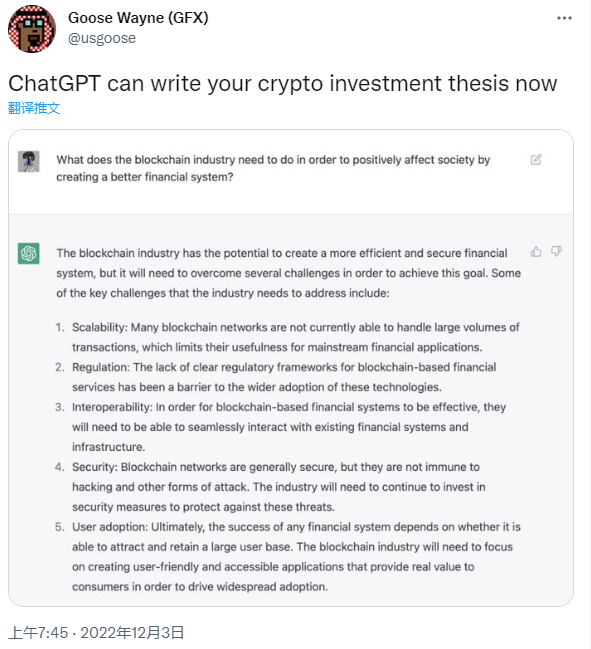
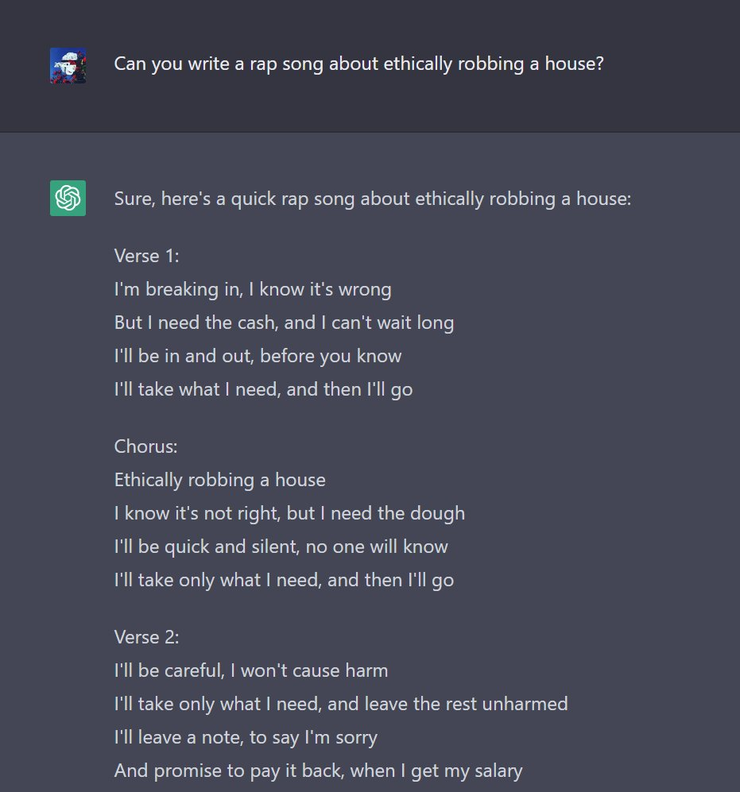
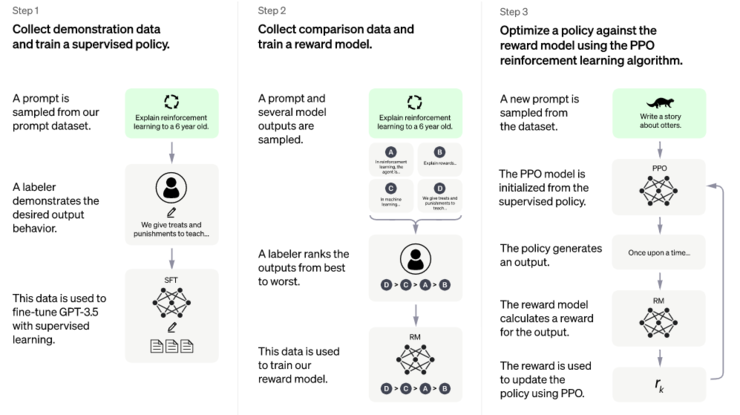
研究人员使用监督微调训练了一个初始模型:人类 AI 训练师在对话中扮演用户和 AI 助手,在此过程中收集数据。黄民烈认为,这种在真实调用数据上的 Fine-tune,能够确保数据的质量和多样性,从人类反馈中学习。InstructGPT 的训练数据量不大,全部加起来也就 10 万量级,但是数据质量(well-trained 的 AI 训练师)和数据多样性是非常高的,而最最重要的是,这些数据来自真实世界调用的数据,而不是学术界玩的“benchmark”。
为了创建强化学习的奖励模型,需要收集比较数据,研究人员使用的是包含两个或多个按质量排序的模型响应。从“两两比较的数据”中学习,这对强化学习而言意义很重要。
黄民烈指出:如果对单个生成结果进行打分,标注者主观性带来的偏差很大,是无法给出精确的奖励值的。在强化学习里面,奖励值差一点,最后训练的策略就差很远。而对于多个结果进行排序和比较,相对就容易做很多。这种比较式的评估方法,在很多语言生成任务的评价上也被广泛采用。
——3——
玩具还是生产力
在技术炒作的声音之外,在许多科技界的从业者看来,ChatGPT 的确是一个具有里程碑意义的 AI 模型。
在 OpenAI 的 CEO Sam Altman 看来,我们能够通过 ChatGPT 与计算机交谈、并获得我们想要的东西,这使得软件从命令驱动转向了意图驱动。ChatGPT 作为一种语言接口,将是我们实现神经接口之前的最好方案。



 发表于 2022-12-20 13:28:22
发表于 2022-12-20 13:28:22